PodPod
Podcast explorer with natural language
Tags: AI, LLMs, Audio, Web
About the project
Large Language Models (LLMs) create a new paradigm for interacting with content. PodPod is an interface that allows you to dive deeper into episodes of the "How I Built Using" podcast using natural language.
Try out the app! Use the access token demo--JCEKDg1DS1.
Exploring content with natural language
After listening to hundreds of hours of the "How I Built This" (HIBT) podcast, my wife and I constantly try to remember specifics about episodes and extract insights from many of them: which founder said what about fundraising, which episodes cover supply chain challenges, or which episodes feature founders from a similar background to ours. Could I use LLMs to build a podcast exploration app?
AI Engineering can seem confusing to software engineers. Are we now building applications in a completely new way? Do we still need to implement deterministic business logic? Can we funnel all of our logic into a single intelligent entity, called a Large Language Model (LLM), and have assurance that things just work?
Before this project, I built smaller AI-based applications such as a mobile app that takes photos when people smile using local CV models, and an automated messaging system for restaurants. Those explored very punctual and narrow problem spaces without concerning myself with a production-ready deployment. With PodPod, I wanted to explore building an end-to-end AI-based tool that combines different techniques to create a delightful user experience and put it in front of users - what better excuse than this to build an interface to explore one of my favorite podcasts, "How I Built This".
Technical objectives
From the very beginning, I challenged myself to use the most modern and industry-accepted tools without necessarily having much experience with them. These are the guiding principles for the project:
- Build AI-first
- Provide a great UX
- Expose just enough controls in a chat-based interface
- Utilize a modern stack
- Leverage open standards (primarily RSS)
Implementation
From a high-level perspective, the problem was broken down into the following smaller problems:
- Consume episode data from a reliable source
- Transcribe episodes
- Store transcripts in a searchable data store (via RAG)
- Expose data to clients
- Build a user interface for interacting with the data
- Ensure the system works as intended
To my surprise, RSS feeds, which are free and open by nature, already exist for podcast outlets, and it's totally fair and easy to use them - you can click here to see the feed for HIBT.
Data pipeline
To go from interview audio to searchable data, content needs to undergo a few transformations. This is PodPod's content pipeline:
- RSS feed consumed once per day. Find new episodes after the start date.
- Episode files are transcribed
- Transcriptions are processed into chunks and filtered to remove ads - using a turn-based chunking strategy.
- Chunks are converted to vector embeddings & documents, and stored in a vector database.
- Additional metadata is stored in a relational database
Transcriptions
There are several transcription-as-a-service companies out there whose ethos is to make this process as simple and accurate as possible. I naturally started using OpenAI's Whisper model due to its industry-wide adoption, low cost, and fair pricing. To my surprise, it does not natively support turn-based audio input with multiple speakers, the essence of an interview. The model will give you a transcription, but as of September 2025, it will not contain utterances with speaker tags and timestamps - this metadata is crucial in a RAG-based system, so Whipser could not be the path forward.
AssemblyAI has a very powerful speech-to-text Speaker Diarization model that fits the bill perfectly. After some experimentation with both local and hosted audio files, it was clear that it would perform much better, and it was chosen as the transcription service for the data pipeline.
Processing and chunking
Transcriptions come as utterance objects that need to be transformed into something more usable for our system, and not all are relevant - for example, ads might confuse LLMs when ingesting episode data, so removing them creates better results.
How do you chunk (split) episode transcripts to give maximum versatility to an LLM while keeping the RAG pipeline simple?
I initially implemented a recursive chunking strategy using LangChain's RecursiveCharacterTextSplitter. This splits the entire transcript at occurrences of a given separator - for each resulting chunk, it'll keep all that match the chunkSize param, or continue to split recursively.
This can be a good strategy for many use-cases, but given that interview speech is very segmented by nature, I wanted to try chunking by turn in the hopes of getting more accurate and narrow responses. I wrote a simple chunking strategy to do so, creating a turn object with speaker labels, timestamps, content, and duration per utterance in the transcript. These turns were then filtered in an attempt to remove ads (not always possible) and indexed into a Chroma local collection.
I used Chroma as the vector database due to its simplicity, speed, and ease of use in a production environment where collection sizes are not expected to grow drastically - each episode might contain anywhere from 120 to 300 utterances, depending on the duration and conversation rhythm.
Chroma also comes with a local embeddings model (all-minilm-l6-v2) that makes things easier to get started. I initially used it, but after deploying to a VPS in Render.com, I quickly encountered out-of-memory errors due to the model running on-device and taking ~500MB of RAM, coming mostly from the ONNX Runtime used internally. I ended up switching to OpenAI's embeddings model (text-embedding-3-small), mostly due to its incredibly low latency and cost - Chroma makes this switch very easy by supporting multiple embedding functions.
Episode metadata
The RSS feed contains everything needed to ingest episodes, but there isn't much about the episode itself other than its name, duration, enclosure (URL), and author. Manually adding metadata is definitely an option, but with the trade-off of needing human intervention to run the pipeline. Turns out, LLM are great for solving this problem. I experimented using Sonnet 4 and Haiku 3.5 to generate metadata objects, only giving the episode title as an input. Haiku struggled to generate the correct industries values and to sometimes structure the output as JSON, while Sonnet crushed this very simple task. To guarantee that the output is usable every time, all responses are passed through a pydantic validation step, returning a safe default when the metadata is not JSON.
Querying, searching, and streaming
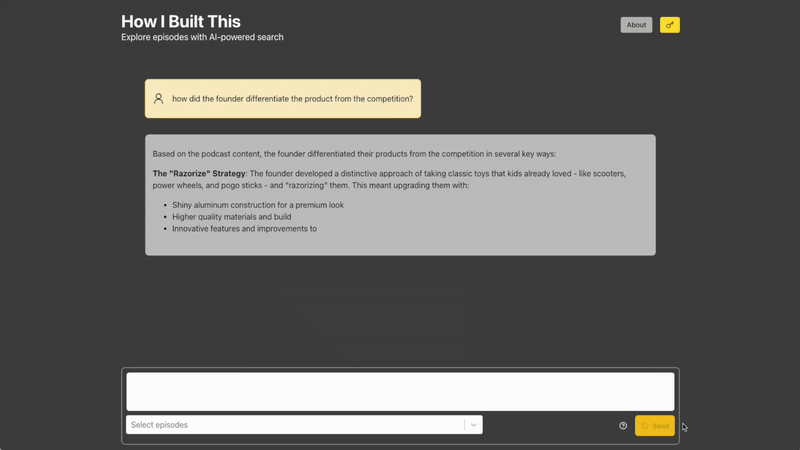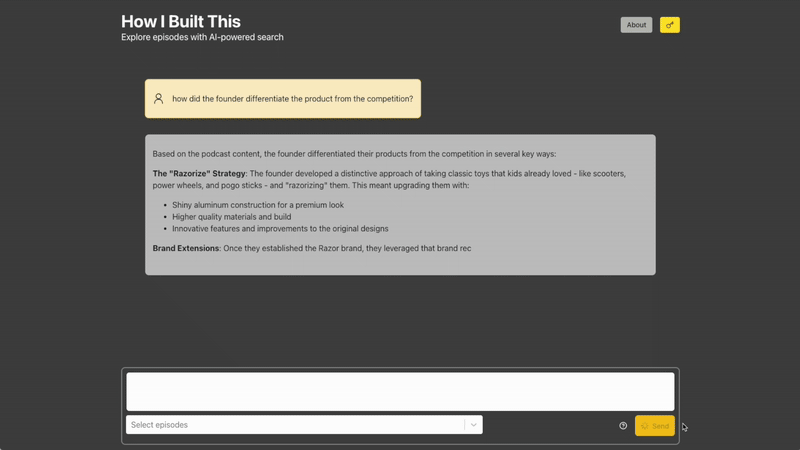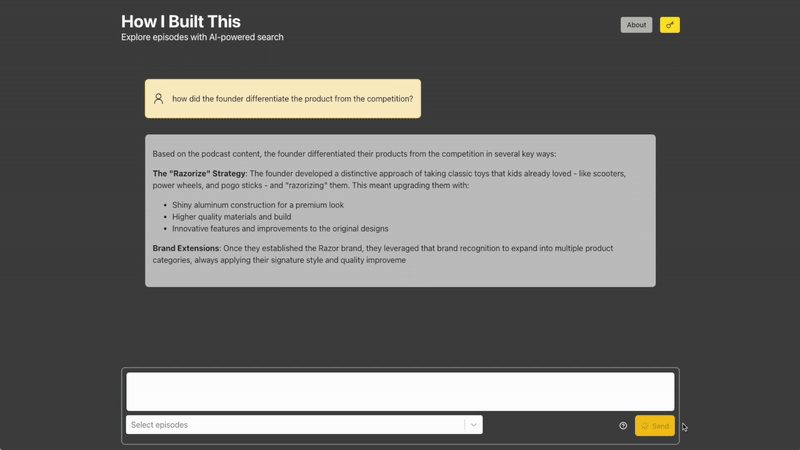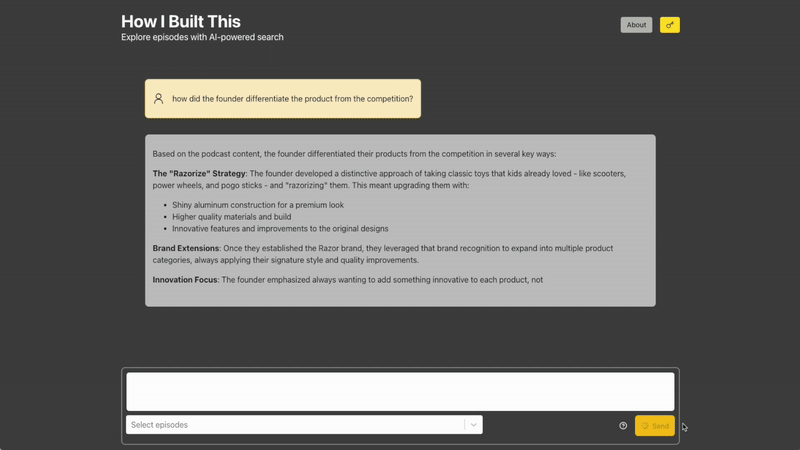
PodPod serves RESTful endpoints using FastAPI, which I found to be a delightful framework - the main POST /answers endpoint exposes an interface to generate answers. Upon request, the user's query is expanded to improve its relevance against all indexed data, is then routed using to one of several query categories ("factual", "comparative", "summary", and so on), and is then fed into the RAG pipeline, where Chroma is queried using the expanded query and the list of episodes that the user specified. Ragas was also used to perform evaluations to help determine how many documents to query (top_k, exposed by Chroma as n_results), and whether or not query expansion helped in any way. I found results to be a bit inconsistent between evaluation runs, but I ultimately settled on using n_results= 5 and keeping query expansion. The injected prompt is then sent to Anthropic, where Sonnet 4 generates a (sometimes) thoughtful and (hopefully) inspiring answer to the user's query as well as the retrieved documents, which are displayed as the citations.
Streaming and client-side consumption
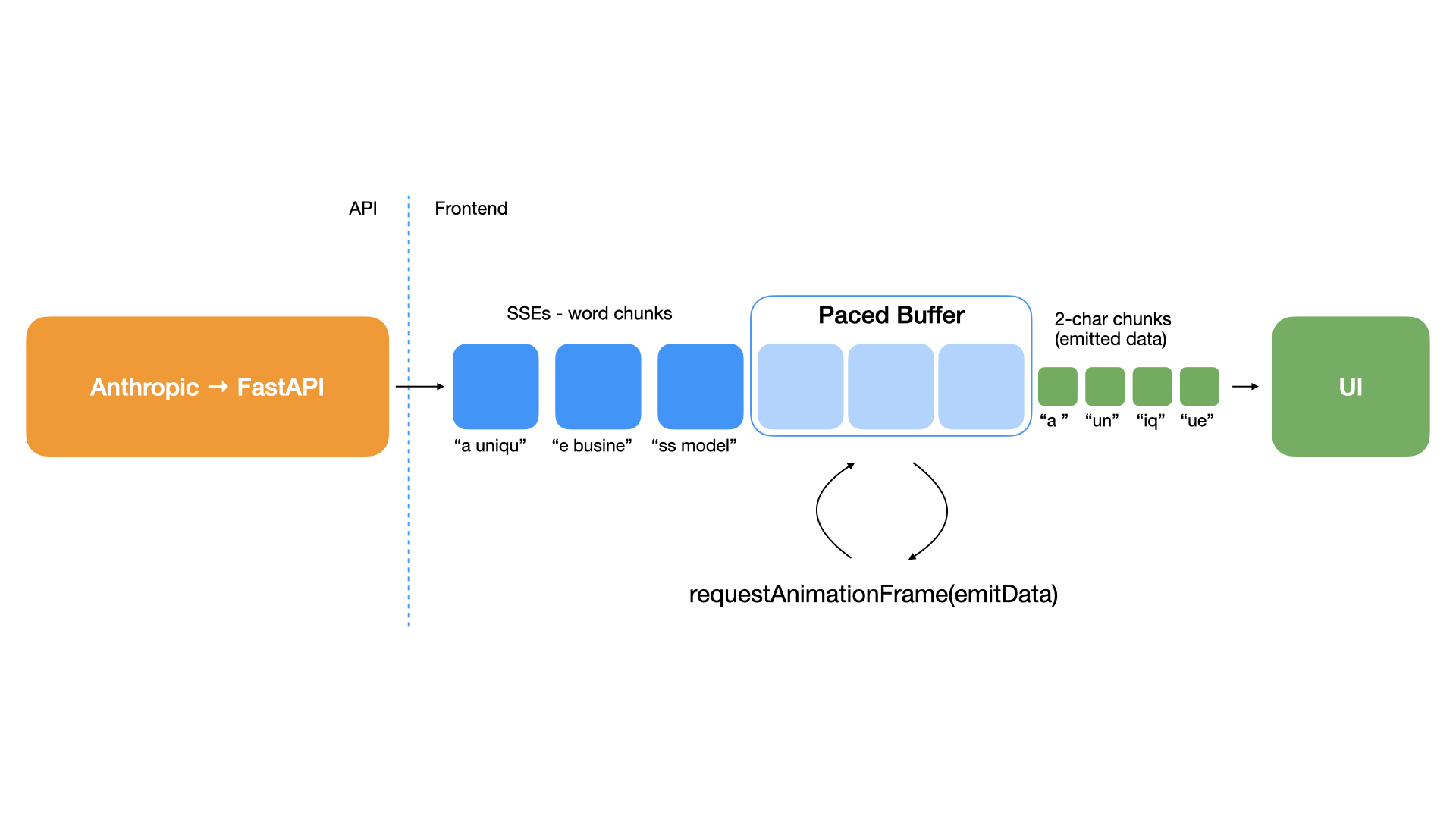
Answers and citations (retrieved documents) are streamed from FastAPI to the frontend over Server-Sent Events (SSEs). The client React app uses a custom-built stream client that wraps @microsoft/fetch-event-source and exposes a series of handy and ergonomic utilities to make state management a breeze.
Anthropic's streaming response comes in unknown chunk sizes and in an unknown cadence. Additionally, there is unavoidable latency in streaming from Anthropic → API → Client. If naively implementing stream consumption in the client, answers would be rendered in lagging word chunks. I wanted to create a better user experience than that, ideally with a smooth typewriter-like effect, so answer chunks coming through SSEs events in the client are buffered, and a custom pacer grabs the next 2 characters every 2 frames (using requestAnimationFrame), seamlessly updating the UI. These small UX details matter because they make reading the responses a much more pleasant experience.
Results, limitations, and learnings
The end result is a great, snappy app that has taught me a lot about founders and companies I am interested in. The API is performant, simple to maintain, deploy, and monitor.
This, of course, does not come without technical and UX limitations:
- There is no memory of the conversation between messages - each message has its own context.
- Since the chunking strategy is only turn-based, questions that require the whole episode to compute an answer do not perform well. For example, "What is the tone of the James Dyson interview?".
- Not all episodes are available - only 10-20 of them are, but this number will increase as some kinks are ironed out.
- Ad chunks are not always filtered properly
- Turn chunks sometimes do not contain a speaker label - this comes from the limitations of AssemblyAI, as it does not always cluster utterances properly.
Learnings
- LLM-based evaluations (RAGAS) have a high token consumption, and the results are not always conclusive. I need to spend more time diving deeper into this area.
- Transcription models, no matter how good they perform, are going to make mistakes. Your content pipeline should account for this, and correction strategies should be implemented if the small percentage of data loss is important for your application.
- LLM adoption in an application can scatter like wildfire. Initially, I only used an LLM to generate answers with the retrieval-augmented contexts, but I soon found myself using them to route queries, expand queries, generate episode metadata, and perform many other small tasks. All of these calls add latency. If keeping latency and cost as low as possible is a requirement for you, using Small Language Models (SLMs), self-hosted, or on-device models is probably a better approach.
- LLMs make a lot of mistakes even on small tasks. Always validate your response structure, and provide a sane default - my query routing task would sometimes fail, so defaulting the category to
"factual"is a safe bet. Pydantic (python) and Zod (TS) make this very simple in dynamic languages. - Chunking is a rabbit hole you can go down into. There are countless ways to slice up your data. Pick one (or a few) strategy that gives your application the most versatility possible - for PodPod, indexing the whole episode transcript as well as the turns would have probably been the better approach.
- LangChain offers a lot of convenient utilities, but you are fine without them - I ended up rolling my own and removing any LangChain packages from the project.
Thanks for reading!
Tools
- Python
- FastAPI
- Docker
- Claude Sonnet 4 and Haiku 3.5
- OpenAI Embeddings Model
- AssemblyAI
- ChromaDB
- SQLite
- Render.com
- Ragas
- React
- TypeScript
- RadixUI
'/%3e%3c/svg%3e)

'%3e%3cpath%20d='m1770%205113c-505-14-749-59-1008-185-286-140-533-421-641-731-109-313-126-567-118-1787%207-1042%2020-1199%20118-1479%20114-324%20341-587%20635-737%20246-125%20445-166%20903-185%20310-14%201779-6%201986%2010%20314%2025%20503%2071%20713%20173%20296%20145%20543%20434%20650%20760%20101%20307%20117%20561%20109%201763-7%201037-20%201194-118%201474-114%20324-341%20587-635%20737-241%20122-447%20166-872%20184-196%208-1448%2011-1722%203zm1697-463c334-14%20491-42%20649-114%20185-86%20339-240%20419-421%2059-135%2087-267%20107-515%2018-219%2018-1953%200-2134-32-335-103-522-261-688-180-190-376-267-761-298-202-17-1599-25-1930-11-377%2015-523%2040-688%20116-182%2085-337%20241-417%20420-59%20135-87%20268-107%20515-18%20218-18%201953%200%202134%2032%20334%20102%20519%20260%20687%20213%20227%20458%20299%201062%20312%20331%208%201466%205%201667-3z'/%3e%3cpath%20d='m3880%204229c-99-15-185-77-230-166-35-67-36-196-2-264%2094-192%20352-233%20495-80%20198%20212%2022%20552-263%20510z'/%3e%3cpath%20d='m2340%203855c-282-52-529-183-721-382-169-174-275-368-337-610-25-99-27-124-27-303s2-204%2027-303c153-602%20666-1007%201278-1007%20299%200%20563%2089%20800%20271%20236%20180%20402%20434%20476%20731%2032%20127%2043%20359%2025%20489-78%20535-464%20961-993%201095-87%2022-130%2027-278%2030-120%202-198-1-250-11zm470-480c272-86%20476-289%20566-565%2026-79%2028-97%2028-250s-2-171-28-250c-90-275-290-475-566-566-79-26-96-28-250-28-153%200-171%202-250%2028-275%2090-476%20290-566%20566-26%2079-28%2096-28%20250s2%20171%2028%20250c99%20303%20328%20512%20641%20586%2042%209%20102%2013%20200%2010%20118-3%20154-8%20225-31z'/%3e%3c/g%3e%3c/svg%3e)
